Explaining Articles using LLMs
January 29, 2024
Natural Language Processing is the backbone of Language Models. They are used in a variety of tasks such as Machine Translation, Text Summarization, Question Answering, etc. This writing tries to understand how LLMs can be used to explain articles by using the pre-trained LLMs exposed on APIs such as OpenAI and GPT3.5 and how they can used for the task of article summarization, keyword generation, etc.

Architecture
The system uses a Flask backend which has been deployed as a backend service interacting with Celery workers and Redis for data caching. The architecture of the project is shown in the figure below which is a representation of the data pipeline and how different tasks like summarization, keyword generation can be handled by this pipeline.
The pipeline leverages OpenAI’s GPT3.5 turbo at various steps and in custom in-context learning settings. We employ OpenAI’s GPT3.5 to condense the provided text, leveraging its refined training model that incorporates human feedback.
Summarization not only reduces length but also enhances semantic nuances often overlooked in lengthier texts. Next, we utilize OpenAI’s GPT3.5 once more for keyword extraction, employing a tailored in-context prompt based on semantic representations obtained through the text-embedding-3 model.
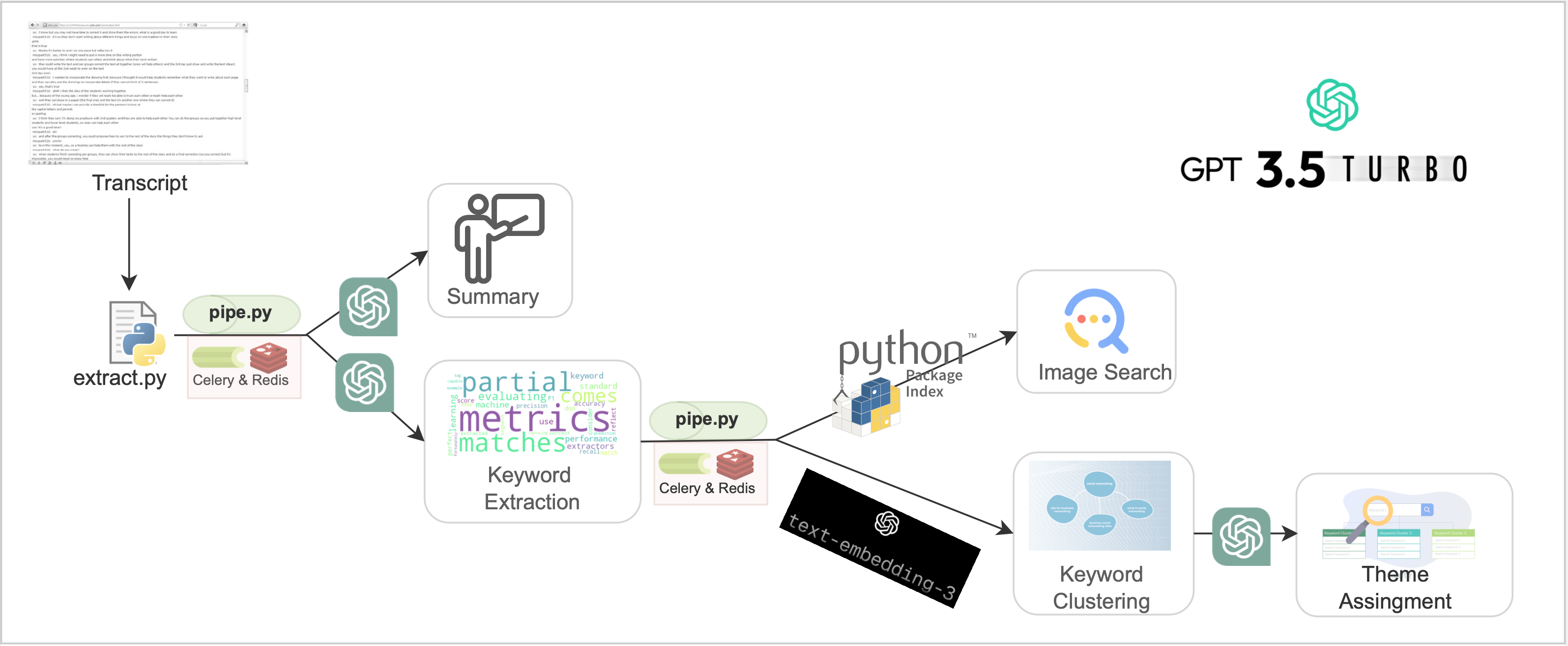
Rather than employing basic document grouping, we opt for topic modeling using the K-means algorithm to identify embeddings, facilitating clustering with descriptive labels for each cluster. This approach aids in thematic assignment to clusters, with findings suggesting that OpenAI’s extracted themes better capture the essence of keyword clusters.
Lastly, to enhance comprehension, images corresponding to each keyword/keyphrase are retrieved using Google Image Search.
Directory Structure

The directory structure of the project is shown in the figure beside which can also be seen on Github here. The repository is kept private because of plagiarism reasons.
While the segregation of folders and their respective functions is understood, the apis directory incorporates all the APIs using Flask Blueprints that have been registed in main.py.
The celerey_ directory is resposible for controlling and initializing celery and the exceptions directory is used to handle a CustomErrors.
Integration of OpenAI APIs for processing pipeline tasks like Summarization, Keyword Extraction & Clustering and Theme Assignment are kept under utils.py as utility functions or helper functions for integrating the above mentioned modules.
Config variables like max_tokens for the API keys of GPt 3.5 Turbo and Embedding Models are located under cfg.py followed by the google-search_key and engine_key for finding image-addresses.
Installation
Whenever dealing with python based applications, it is a very good practice to make a virtual environment and then deal with the process of installing libraries and dependencies as the installation then affects one particular environment. One can use any virtual environment to inilise this project by either using venv or conda.
Next, we need to make sure that our dependies are in order, so we will use the following command to run the requirements for this project. The command is as follows:
pip install -r requirements.txt
After the successfull installation of the libraries and dependencies, we will proceed forward to run the application by running the server from main.py. The command is as follows:
python3.8 main.py
Following this, a prompt will be generated displaying that the server is running at the following address.
Running on all addresses (0.0.0.0)
Running on http://127.0.0.1:3000
Running on http://192.168.1.146:3000

While this flask server is running, we need to make sure that that the redis-server is running in another terminal tab. If redis is not installed in your system, one can use:
sudo apt install redis-server OR brew install redis --> For installing redis
redis-server --> For running redis in the terminal

And lastly, we need to make sure that the celery is also running in another terminal tab, one can use the following command to trigger it:
celery -A celery_.app worker -Q run_pipe_queue -n pipe_task_worker@%h --loglevel=INFO

This will essentially triggers pipe.py which handles the complete pipeline under pipe() function which is interleaved with utils.py utility or helper functions for the process of summarization and keyword clustering.
Postman Usage
In order to mimick an actual API hit for this pipeline, an example or dummy text will be taken under Body > raw and selecting JSON while the API endpoint will be hit using Postman to receive a response. The request body is as follows:
{
"text": "A company unveiled this Thursday......."
}
The API endpoint of http://127.0.0.1:3000/pipe is exposed which can be hit using a POST request on Postman to receive the outputs. The response for any news transcript/article would be something like the below screenshot:

The response will be in the form of a JSON file which will be saved under the files directory as ideas.json. The output for any news transcript/article would be as follows in the below screenshot, where:
- raw - Represents the orginal news article or text that needs to summarised.
- summary - As the name suggests is the summary of the raw text.
- keywords - Various keywords selected from the raw text.
- images - Images for the selective keywords from the raw text.
- timestamp - Timestamp for the API completion hit.

This ideas.json can further be ingested periodically to a database or a data lake for further analysis and insights.
Acknowledgements & Feedback
I am deeply grateful to Karanjot Vilkhu for his invaluable assistance in navigating the complexities of risk analysis in the context of this project. His unwavering support and encouragement have propelled me to surpass my limitations, fostering a culture of perpetual growth and development.
Furthermore, I welcome any suggestions or feedback on this piece, which reflects my personal insights and knowledge gained throughout my journey. I sincerely hope that it proves beneficial and accessible to all who engage with it.